A note on this post: This is a technical deep dive. We go into architecture decisions, failure taxonomies, SQL, and production error rates in detail. If you're here for the high level story, the first and last sections will get you there. If you want to understand how to build reliable systems on top of unreliable LLMs, the middle section is for you.
A 4:58 AM wake-up call
On a Tuesday early this year, a data build tool (dbt) production run failed at 4:58 AM. A surrogate key logic error in our staging layer was silently producing duplicate rows: the kind of bug that doesn't announce itself until something downstream breaks.
Normally, this would mean 45 minutes of an on-call engineer's morning: digging through Snowflake audit logs, tracing the error upstream through our layered architecture, filing a Jira ticket, and opening a pull request (PR) with the fix. By the time they'd context-switched into the problem, half the morning was gone.
But that Tuesday was different. By the time our on-call engineer logged in, the root cause was already identified, a Jira ticket was drafted, and a PR was ready for review. The only thing left was to read, approve, and merge.
This is the story of De-Bug-T, a debugging system we built at Headway. It started as a hackathon project. It's now how our team handles dbt failures in production.
This post explains how we built it, what we got wrong, and the engineering principle that made it work: treat the Large Language Model (LLM) as an unreliable component in a reliable system.
The problem: Debugging a DAG at 5 AM is no one's idea of fun
Headway's data platform runs on dbt and Snowflake, organized in a medallion architecture: raw sources flow into staging models, then into refined fact and dimension tables. When something breaks, the failure you see is often several layers removed from where things actually went wrong.
Debugging means traversing this directed acyclic graph (DAG) by hand, and it follows roughly the same playbook every time:
- Find the failing model and read the error
- Check if sibling models in the same run also failed
- Trace upstream: fact, intermediate, staging, base, source
- Identify whether it's a code bug, infrastructure issue, or data quality problem
- Fix it, file a ticket, open a PR
If the troubleshooting playbook is deterministic, the troubleshooter shouldn't have to be human.
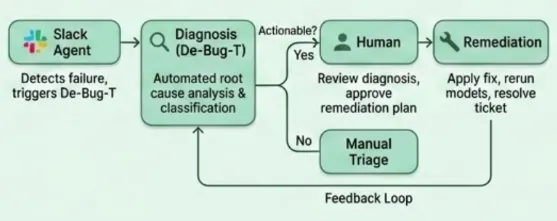
Tools like Elementary and Monte Carlo solve the detection half of this problem well: they monitor for anomalies, fire alerts, and tell you something is wrong. But they stop at the alert. The on-call engineer still has to open a terminal, trace the DAG, figure out why something is wrong, and decide what to do about it. De-Bug-T starts where those tools stop. The input is an alert that has already fired. The output is a root cause, a fix, and a ticket.
The bet
During Headway's 2026 hackathon, I built De-Bug-T (yes, it's a pun. I'm committed to the bit). The idea was simple: take the debugging runbook our team already follows and encode it as structured steps an LLM agent can execute on.
The bet was that an LLM could do something surprisingly well: trace errors through a DAG. DAG traversal is structured, the error patterns are classifiable, and the investigation steps are well-defined. It's a problem that's tedious for humans but well-suited for AI that can query logs and read code without getting bored at 5 AM.
But I didn't bet on the LLM being reliable. I bet on making each failure recoverable.
The architecture: Constrain the LLM, not the outcome
Each key design choice in De-Bug-T follows one principle: reduce the space of things the LLM needs to figure out on its own.
None of these components are novel on their own: audit log queries, error taxonomies, and PR automation all exist independently. The innovation is wiring them into a single feedback loop where the LLM orchestrates the sequence: detect, classify, trace, diagnose, report, with each step constraining the next.
- Error classification uses a lookup table, not open-ended reasoning. Pattern-match against 11 known failure signatures. Don't diagnose from first principles.
- DAG traversal follows a fixed layer order. Mart, intermediate, staging, base, source. The LLM decides whether a layer has a problem, never which layer to visit next.
- Diagnostic queries are templatized. The LLM fills in model names and date filters; the query structure is pre-written and references our context documents. A hallucinated column name produces a failed query, not a wrong diagnosis.
- An architecture reference doc lists layer conventions and valid schema paths so the LLM doesn't have to guess.
The core diagnostic compares row counts across every layer of the DAG to find where quality first diverged:
WITH layer_counts AS (
SELECT 'source' as layer, 1 as ord, COUNT(*) as row_count
FROM raw.source.table WHERE DATE(created_at) = '2026-02-11'
UNION ALL
SELECT 'staging', 2, COUNT(*) FROM staging.stg_table
UNION ALL
SELECT 'intermediate', 3, COUNT(*) FROM staging.int_table
UNION ALL
SELECT 'mart', 4, COUNT(*) FROM refined.fct_table
)
SELECT layer, row_count,
row_count - LAG(row_count) OVER (ORDER BY ord) as rows_lost
FROM layer_counts ORDER BY ord;
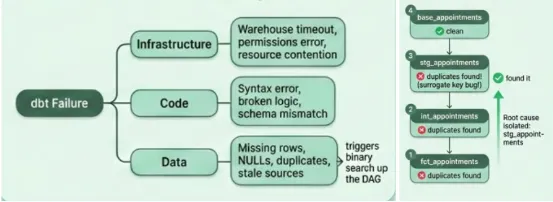
When the LLM sees rows_lost = -2,500 at intermediate, it knows exactly where to investigate next. The entire upstream trace is a loop: run this query, find the first layer with a problem, read that layer's SQL, repeat one level up.
The system is two skills that chain together. The debugger runs the investigation. The remediation skill fires only when an engineer decides to proceed. It drafts the fix, opens a PR, and creates a Jira ticket.
The Slack integration: Eddy and De-Bug-T
De-Bug-T runs as a skill inside Eddy, Headway's internal AI platform built on Claude's SDK and connected via MCP to the systems where our work lives. When a dbt failure fires in the #data_notifications channel, an engineer tags Eddy; it runs the debugger skill against Snowflake and threads the diagnosis back into the same Slack message within a few minutes.
The design decision here was to keep the trigger manual rather than fully automatic. An engineer still summons the investigation, they just don't have to conduct it. The on-call engineer's workflow shifts from "let me spend 45 minutes figuring out what happened" to "let me spend 5 minutes reading what happened and deciding what to do."
Why we kept humans in the loop
Early on, we considered chaining both skills to run end-to-end without intervention. Then reality intervened.
A few days after deploying the Slack agent, it correctly diagnosed a batch of dbt failures as transient Snowflake warehouse errors. If alerts had fired automatically, it would have created unnecessary Jira tickets and PRs for problems that didn't need fixing.
The production data made the case decisively. Of the diagnoses over five weeks, 83% required no action at all. Only 17% led to any remediation.
Results
During that first 4:58 AM incident (the surrogate key failure that kicked this all off), the debugger cut active troubleshooting time by roughly 88%. Your mileage will vary: complex data quality issues still need human investigation. But for a majority of failure patterns (key collisions, schema mismatches, incremental logic errors), the debugger handles the grunt work reliably. We know which category we're in from the classification step, so the engineer reading the Slack diagnosis knows immediately whether it's a rubber-stamp or a judgment call.

Since going live, the Slack agent has run 115 automated diagnoses, averaging 7.5 Snowflake queries per investigation at a median LLM cost of $1.60 per run. $1.60 of compute replacing ~45 minutes of engineer context-switching is not a marginal improvement.
When the LLM gets it wrong
When we first went to production, about 25% of the debugger's Snowflake queries failed at the warehouse. The LLM would hallucinate column names or reference schemas that didn't exist. An architecture reference doc helped, but didn't solve it.
Since then, our data team built a context registry on top of the warehouse that provides agents (including De-Bug-T) with table documentation, required filters, and valid schema paths at query time. That brought the failure rate down to roughly 13% in the most recent week.
Because we constrained the LLM to templatized queries, a hallucination costs one failed query, not a wrong diagnosis. The query returns an error. The LLM retries with a corrected schema path. The investigation continues. Each step produces a verifiable intermediate result: a row count, an error message, a model name, that either confirms or contradicts the hypothesis. The LLM never makes a single high-stakes leap. It makes a series of low-stakes, checkable moves.
If you're building LLM tooling for production, the question worth asking isn't "how do I make the model more accurate?" It's "how do I make each failure recoverable?"
Lessons learned
Know when to automate, and when to stop. The data taught us that automating the investigation is high-value, but automating the decision would have destroyed trust.
Invest in failure classification early. The current taxonomy covers the common cases well, but edge cases (e.g., intermittent upstream API drift) still need human eyes. Each month in production teaches us new patterns. A richer pattern library would help. If I were starting over, without the hackathon time crunch, I'd build the taxonomy as a living doc from day one.
Treat operational setup with the same care as code. The Slack agent was initially tied to my personal Eddy account, which meant no one could manage it if I wasn't responsive (oops). We've since moved to shared credentials, but I should have set that up from the start.
De-Bug-T started as a hackathon project and a silly pun. It's now how our team handles dbt failures in production. If your team's playbook fits in a Markdown file, it can probably run itself.
What's next
The next version of De-Bug-T will get smarter: the context registry keeps improving, the failure taxonomy keeps growing, and each month in production teaches it new patterns. But De-Bug-T was never really about dbt. It was about a bet: that you can build reliable systems on top of unreliable models if you constrain the right things. The 4:58 AM incident proved the bet pays off for one domain. We're now testing whether it holds for others. So far, the playbook travels.
At Headway, we're building a new mental healthcare system that everyone can access. That means solving hard engineering problems: in data infrastructure, in AI, and across each layer of the stack. If that sounds interesting to you, come build with us.


