At Headway, our backlog had over 1,000 items. Some were over three years old. These issues spanned slow pages, dead feature flags, broken links, flaky tests, and more. It's the kind of work that is hard to carve out time to prioritize, but collectively adds up over time.
We called it the broccoli of engineering. Everyone knows it's good for you, but nobody wants to eat it. So we built a system where AI agents eat the broccoli for you. In eight weeks, it shipped 250+ pull requests with zero human-written code, with every line human-reviewed. Building a new mental healthcare system that everyone can access takes a lot of work, and we're proud of the improvements in quality we've been able to achieve with AI's help. This post is about the architecture, the sharp edges we hit, and what we learned about building multi-agent systems.
The problem with "just file a ticket"
Headway is a multi-sided marketplace connecting patients to mental health care providers. Our backend is a Python/FastAPI monolith; our frontend spans four React apps. At our scale of tens of thousands of providers and millions of monthly patient interactions, paper cuts in the product add up. A slow page could cause a patient to become discouraged while finding a provider. A confusing error message gets a patient stuck mid-booking. Noisy test output hides real failures.
None of these are incidents. They don't page anyone at 2 AM. But they chip away at quality at the margins, and we hold a high bar for the experience we want patients and providers to have on Headway.
The standard playbook is to file tickets and prioritize them against feature work, which in practice means they never get prioritized. Dedicated tech debt sprints (such as "Craftway," our annual quality-improvement week) help, but can't keep pace with the rate at which small issues accumulate, especially in an AI-enabled development environment with increased product velocity.
We needed something that could run continuously, work from a structured backlog, and produce changes a human could review in two minutes.
What we built
A worker pool is a set of autonomous Eddy agents (Eddy is Headway's internal AI platform) that triages issues, writes code, opens pull requests, and babysits those PRs through CI and code review. The engineer's role is scoped to one important job: approve or reject the PR.
The architecture has three components: a dispatcher, a set of workers, and a notifier.
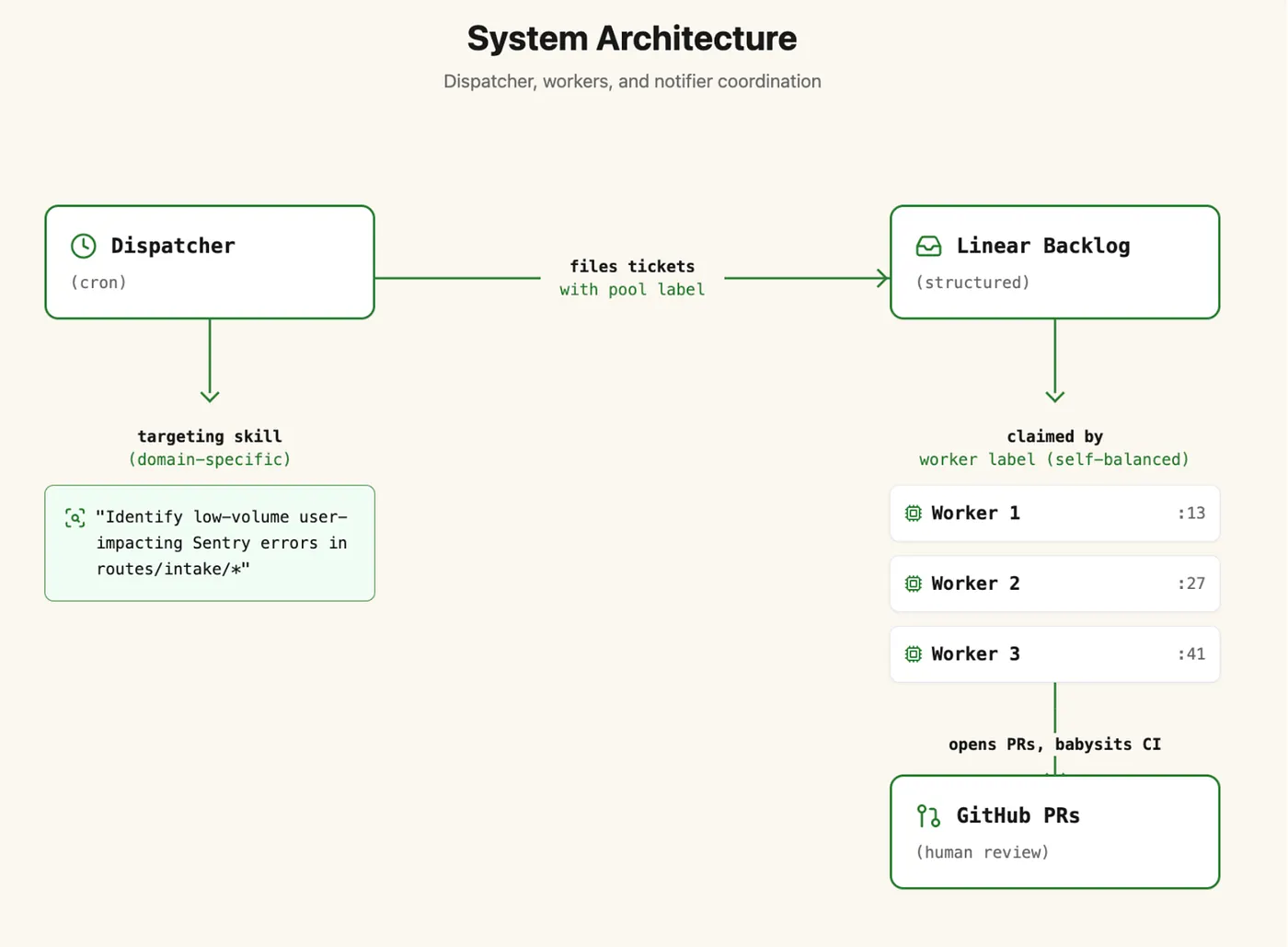
The dispatcher
The dispatcher runs on a cron schedule, typically weekly. Its job is to scan for new work and file tickets. Each pool has a targeting skill: a narrow, domain-specific auditor that knows how to find problems.
For example, for our accessibility pool, the targeting skill runs axe-core against route components and files tickets for each finding. For page performance, it profiles Lighthouse scores. For broken links, it crawls href attributes against known routes. The targeting skill is the only part of the system that's domain-specific; everything else is generic infrastructure.
The dispatcher writes structured tickets into a Linear project with a pool-specific label. This is then load balanced with workers only touching tickets carrying their label, sharing responsibility with other domain-scoped workers. They never invent work or self-direct. If it's not in the backlog, it doesn't exist.
The workers
Each pool runs up to three workers. A worker is an Eddy scheduled agent that wakes on a pre-specified cadence, claims a ticket, writes code, opens a PR, and goes back to sleep. On its next wake, it checks on its open PRs (fixing CI failures, responding to review comments) before picking up new work.
Workers are stateless by design. Each wake is a fresh conversation with no memory of prior runs. All context lives in the ticket system: Linear comments (edited in place, not appended, to avoid ballooning the thread), PR descriptions, and CI output. A worker reconstructs its world from these external sources on every wake.
Load balancing is done through labels. Worker 1 claims tickets tagged worker-1, Worker 2 claims worker-2, etc. The dispatcher round-robins assignments. Workers are staggered to avoid thundering-herd problems on shared infrastructure. We learned this the hard way when 15 pools all firing at :00 caused rate-limiting cascades on our code intelligence APIs.
Pools can also be headless. Users can spin up worker pools and attach them to existing epics, without associated dispatcher agents. Teams have regularly used this feature to attach to tech debt backlogs or cross-functional triages.
The notifier
The notifier is the simplest component: a scheduled agent that runs weekly (typically Monday mornings), aggregates all activity for the pool, and posts a summary to a Slack channel or DM. Open PRs awaiting review, merged PRs, blocked tickets. The owner gets a digest without having to monitor anything.
The wake loop
Here's what happens on every worker wake:

The second step (colloquially referred to as the babysitting step) has proven to have a lot of value. A naive system would open PRs and walk away. Ours iterates: if CI fails because of a linting error, the worker reads the CI log, fixes the violation, and pushes. If a reviewer leaves a comment asking to rename a variable, the worker addresses it on the next wake. This turns a one-shot PR into a multi-turn conversation, mediated through Git and Linear rather than through agent memory.
Linear as a knowledge base
Perhaps the most impactful architectural decision was using Linear as the coordination substrate, not just a ticket tracker, but rather a knowledge base to which workers continuously read and write.
Workers store their progress as edited comments on tickets. They don't append new comments (which would create noise); they update a single sticky comment with their current state: which file they're looking at, what approach they're taking, what failed. When a worker wakes up in a new conversation, it reads this comment to reconstruct context. This has proven durable against worker restarts or infra issues.
Linear's native status columns (Backlog, In Progress, In Review, Done) map directly to the lifecycle. The dispatcher creates tickets in Backlog. Workers move them to In Progress when they start coding. When a PR is opened, the ticket moves to In Review. Merged? Done. Rejected? Back to Backlog with a comment explaining why. The entire state machine is visible in a single Linear board.
This also makes the system legible to non-engineers. A PM can open the board and see how many items the pool has processed, what's stuck, what's been rejected. We have seen several cross-functional partners spin up worker pools for their own use cases.
Challenges we encountered
Thundering herds
When 15 pools all scheduled their workers at the top of the hour, our Temporal scheduler hit concurrency limits. The fix was a per-schedule jitter: a job scheduled for 9:00 AM actually fires at a random time between 9:00 and 9:05. We also rate-limited new conversation creation to 3/second. Workers within a pool are manually staggered (:13, :31, :47, etc), but the jitter handles cross-pool coordination without requiring pools to know about each other.
Skill ballooning
Our initial implementation was a single monolithic skill (99,000 characters, 2,300 lines) that handled every aspect of the worker lifecycle. It worked, but it was difficult to test, hard to debug, and left too much room for nondeterminism. Reading a list of Linear tickets and filtering by status is not a task that benefits from an LLM's judgment. It's three lines of deterministic code. That observation drove the refactoring toward an inbox/outbox pattern, massively improving our architecture.
Context window resets
Because workers are stateless (each wake is a new conversation), they burn tokens re-caching context on every cycle. A worker that's been babysitting a PR for multiple wakes has to read the ticket, the PR description, the CI logs, and the review comments from scratch every time. This is expensive and can cause the agent to lose the thread of a multi-turn review conversation.
The stateless design was intentional (no conversation-level persistence existed when we started), but it has real costs. The "Eddy as an Assignee" architecture we're building now solves this by routing all events for a single issue into one persistent conversation.
Event driven architecture
The cron-based architecture works. It's also fundamentally limited by its polling model. A worker that fires hourly can't react to a reviewer's comment until the next wake, potentially 59 minutes later. The round-trip from "reviewer leaves comment" to "worker addresses it" averages 30 minutes. For the kind of small fixes we're shipping, that's tolerable. For anything more interactive, it's too slow.
Our new architecture inverts the control flow: instead of workers polling for work on a schedule, events push work to agents.
What we learned about multi-agent systems
Agents need a structured world
Early experiments let agents work from free-text Slack messages. The result was duplicate work, colliding PRs, and agents interpreting the same request differently. Moving to Linear, with its structured fields, status columns, labels, and comments, eliminated an entire class of coordination failures.
The general principle: the less ambiguity in the agent's environment, the less you need the agent to exercise judgment. And judgment is where hallucination lives. This is where our later improvements most made a difference: determinism. Our deployment of deterministic, verifiable steps in place of large skills led to a large improvement in pool performance.
Agent-to-agent communication is the unlock
Our workers communicate through artifacts: labels for load balancing, ticket comments for state, PR descriptions for context, CI output for feedback. This enables a great deal of observability and spares us from unnecessary collision, because every interaction is visible in Linear or GitHub and auditable by a human.
The dispatcher-worker-notifier pattern works because the interfaces between agents are well-typed: a ticket with specific fields, a label with a known schema, a PR with a structured description. When we tried to let agents coordinate through natural language, the failure modes were unpredictable. When we forced coordination through structured artifacts, failures became diagnosable.
Scope narrowness is an engineering constraint
"Keep tasks small" is not just a UX preference, it's a hard constraint driven by two failure modes that compound:
- Hallucination rate scales with scope. A small accessibility fix hallucinates rarely. A 200-line feature implementation hallucinates frequently due to ambiguity and subjectivity.
- Review burden scales superlinearly. As PR volume explodes due to the productivity unlock of agents, review burden cannot keep up if PRs are massive in size. Keeping well scoped, defined PRs with reasonable length is imperative.
Results
Eight weeks after launch, here are the results:
- 250+ PRs (merged + in-review)
- 20+ engineers across every engineering org running active pools
- Zero lines of human-written code (with full human review)
- Performance: 20% LCP improvement on patient-facing growth pages. LCP, or "Largest Contentful Paint" is a key Google performance metric that measures how long it takes for the main content of a webpage to load and become visible to the user.
- Growth: 25+ mechanical SEO fixes shipped
- Bug discovery: Removed an N+1 query in a billing infrastructure endpoint that humans had missed
Teams are using pools for accessibility audits, page performance, experiment flag cleanup, CSS migrations, broken link scanning, test anti-pattern cleanup, and last-mile polish for feature launches. The velocity is not slowing, either. We have seen steady week-over-week usage of the pools since launching to the company roughly 8 weeks ago.
What's next
We are actively shipping the webhook-driven "Eddy as an Assignee" architecture as a follow up to our current system. We are also looking at tiered autonomy where changes are graded based on risk and may require varying levels of approval before shipping. We also believe in extending the pattern beyond code: the same dispatcher/worker architecture works for any domain where there's a structured backlog of defined, repetitive tasks.
The hardest design question was never "can AI write code?" It was: how do we architect multi agent systems in a safe, reliable way? The answer, it turns out, ends up being the same as for humans: defined scope, clear ownership, and a culture that treats automated PRs with the same rigor as handwritten ones.
A note on building this
Worker pools started as a side project: a few evening hacking sessions, a shared Google doc full of half-baked ideas, and a growing conviction that the tooling was good enough to try something ambitious with it.
The part worth emphasizing is that we didn't need special access or a dedicated AI initiative. The Eddy platform team had already done the hard work of making Eddy extensible. Scheduled agents, skills, the Cursor cloud agent integration, conversation persistence were all primitives that existed before we showed up. We just wired them together in a way nobody had tried yet.
Many engineers may be familiar with the version of this story where worker pools sit in a backlog as a feature request to the AI team, waiting to get prioritized against their actual roadmap, possibly getting scoped in a far-off quarter. Instead, Headway's unique culture not only enabled us, but encouraged us to take the worker pools from ideation to deployment, and then collaborate with the platform team to harden it. The Eddy team's response wasn't "why didn't you ask us first", it was "cool, how can we make the platform better for this use case?"
If building multi-agent systems for healthcare infrastructure sounds interesting, we're hiring.